👋 I'm curently looking for a new role. Hire me!
I love a great cocktail. There's something magical about taking a poison that can power a car and make it taste like heaven.

I've been keeping a list of cocktails that I've made and a list of cocktails that I would like to make once I have the ingredients on hand. I kept them as little clusters of bullet points that I published in an app called Workflowy and just sent the link to anyone I happened to talk about it with. When I moved to Obsidian, that online list went away but I still maintained the collection of recipes.
During some time away from work recently, it occurred to me that I could put off countless more important things if I just sat down and got this collection of recipes back online for the ~5 people that have the previous link. So I sat down and did just that.
I have not gone very deep with Eleventy since I converted this whole site earlier this year and I was looking forward to getting to know the data cascade a little better. Most of what I've done on this blog was using template front matter, the blocks of data at the top of the Markdown files that get turned into posts. Everything was defined in the content and there wasn't any reason to generate data of any kind.
But the content that made up these recipes was a bit different:
- The file names were the titles
- Chronological order was not important
- There were specific ingredients that I wanted to call out
This, as well as the URL, all needed to be built programmatically so I wouldn't have to maintain any of those data blocks. I was also hoping I'd find a way to manage my post dates and URLs using their file name instead of explicitly in the front matter.
If you've worked in WordPress before then you're probably familiar with the concept of custom post types. These are developer-defined content types that can be edited and themed differently than the built-in posts and pages. They're great for unique content types like the ones I'm working with here and created the model that I needed in my head:
- I needed a single template file for individual content pieces of this type
- I needed a page where they aggregate
- I needed to parse the content for the ingredients that I wanted to display separately
I started with a layout alias that pointed to an empty template file.
// .eleventy.js
eleventyConfig.addLayoutAlias("cocktail", "layouts/cocktail.njk");This would be the field I would look for when filtering the content into collections. This is not technically necessary but it gives us an easy way to answer the question "how should this content be handled" throughout our code.
Next, I added all the cocktails as Markdown files in their own directory in the main input directory where the rest of my content lives. A few things to call out here:
- The file names are Sentence Capitalized and function as the title for the page
- Individual cocktails recipes are in a
madeornextdirectory, indicating whether I've made them or not - The individual recipes have no front matter at all, everything is generated
The magic here all happens in a template data file. The docs are a little thin on this but there are two "levels" of data here:
- The top-level properties, like
layoutin the linked file above, are pulled as-is and used as defaults. - The properties under
eleventyComputedare generated using template-specific data and will override all previous data.
I set the layout to "cocktail" for everything in that directory and added the layout file to use. This layout looks pretty similar to the post layout with one main difference: content is being passed through a stripSquareBrackets filter that strips out the brackets my note-taking app, Obsidian, uses to link between local files. More on how these are used below.
So, we have a valid layout alias, content to work with, a layout to display that content, and a data file to tie it all together. Now it's time for the eleventyComputed magic!
The easiest was the title and meta_title. Those both come mostly as-is from the file name:
// input/cocktails/cocktails.11tydata.js
module.exports = {
// ...
eleventyComputed: {
title: (data) => data.page.fileSlug,
meta_title: (data) => data.page.fileSlug + " Cocktail Recipe",
// ...
}
};That data.page object has some handy data from the file system as well as a few converted properties:
{
// From the file system:
date: 2021-12-12T01:34:32.174Z,
inputPath: './input/cocktails/next/Yuletide Wave Punch.md',
// Eleventy-generated
fileSlug: 'Yuletide Wave Punch',
filePathStem: '/cocktails/next/Yuletide Wave Punch',
url: '/cocktails/yuletide-wave-punch/',
outputPath: '_dist/cocktails/yuletide-wave-punch/index.html'
}I used the filePathStem to figure out if the recipe was in the "made" group or not and added some content at the top of the recipe indicating it's status.
const madeIt = data.page.filePathStem.includes("/made/");The permalink for the cocktail is built from the file name by replacing non-letter characters with dashes and lower-casing the whole string. You can also use the data.page.url value, appending /index.html at the end. I had a few additional characters to pull out so I went with my own regex.
Finally, I wanted something akin to tags here based on specific ingredients in the recipe. I use Obsidian to manage almost everything I write, including these recipes. It lets you use double square brackets [[Like This]] to link to other, related files. In these recipes, I use them to tie cocktails together by ingredients and keep notes on the specific ingredients themselves.
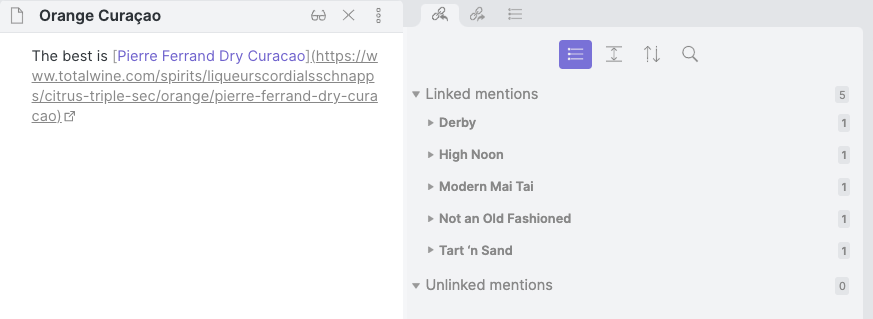
I'm not able to replicate that inter-linking from Obsidian on my blog (yet) but I can use that information to tie cocktail recipes together. The content of the recipe itself is not available in these data files but it's easy to read the contents of the file being processed using the built-in Node file system module fs.
// input/cocktails/cocktails.11tydata.js
module.exports = {
// ...
ingredients: async (data) => {
// Get the absolute path to the file
const filePath = data.page.inputPath.replace("relative path", __dirname);
// Read the file contents
const fileContent = await fs.readFileSync(filePath, "utf8");
// Find all the bracketed content
const ingredients = fileContent.matchAll(/\[\[[\w\d\s]*\]\]/gm);
// Flatten the regex array and get rid of any duplicates
const ingredientsFlat = [...new Set([...ingredients].flat(10))];
// Ditch the brackets
return ingredientsFlat
.map((ingredient) => ingredient
.replace("[[", "")
.replace("]]", ""));
}
};This saves all the ingredients in brackets to an array that I can use to output on the page or find other cocktails that match.
The processing time for ~100 files was not visibly affected by reading the file content at least one extra time per file. If you start to get into the thousands of files, though, this might not be a viable solution. I read through several posts and issues and it was clear that this data had not been loaded by the time these data files are processed.
At this point, we've got the individual cocktail recipes building their own pages but we need a list of cocktails separated by whether I've made them or now. For that, I used 2 custom collections , cocktailsMadeCollection and cocktailsNextCollection, that use the layout property and the presence of the made folder to pull out the custom content types and sort into one or the other. The logic looks like this:
// .eleventy.js
module.exports = function (config) {
config.addCollection("cocktailsMadeCollection", (collection) => {
return collection.getAllSorted().filter((tpl) => {
const hasMadePath = tpl.filePathStem.includes("/made/");
return hasMadePath && "cocktail" === tpl.data.layout;
}).sort(alphaSortTitle);
});
}The "I haven't made this" collection is the same except for the path being checked.
Last but not least, we need a layout to display these collections. With single pages, I always start with a Markdown template to make it easier to add any contextual content. I've had layout files with one-off content in HTML and it just ... felt dirty.
That template points to this layout which counts up and displays the two collections of recipes. The recipes are displayed with their ingredients compiled from the computed data.
And that's that!
I used what I learned to dynamically handle some of the post data as well. Managing posts is a bit easier and less to think about when I create new ones. This all came together quite easily, which is not surprising as that's been the case for the 2 years I've been using Eleventy. If you're looking to start writing on a static site or move over from WordPress, I highly recommend it!
< References >
- The full list of cocktails and my favorite
- PR to add this whole system and the PR to add all the recipes
- Eleventy docs on template data files
- Eleventy docs on collections
- Run-down of the data cascade in Eleventy
< Take Action >
Comment via:
Subscribe via:
< Read More >
Tags
Newer

Jan 11, 2022
Generate new Eleventy post drafts with Hygen
Making new boilerplate files is one of many tiny professional pet peeves that makes me ask "what would a real engineer do?" Answer: automate it!
Older

Dec 12, 2021
We Need Your Beginner's Mind
We need your experiments and your questions and your feedback. Your lack of understanding is a valuable attribute that goes away as you gain experience.