👋 I'm curently looking for a new role. Hire me!
I’ve spent close to a month on partial and full goalie rotation for a team providing open-source SDKs to Auth0 customers and wanted to write out a few of my thoughts on the experience. Overall, I found the experience both satisfying and fun as well as exhausting and frustrating.
Numbers
Here are a few numbers I collected while doing this role:
- ~38 hours on goalie when full time
- ~15 GitHub issues (not including PRs) opened per week (2.5/working day)
- ~3 new ESD issues per week
- ~34.2 Quickstart feedback comments per week (6.8/working day)
Current status:
- 588 open issues and PRs across multiple organizations (300+ to be closed as stale)
- 29 open documentation issues and 11 open documentation PRs
- 19 open primary interrupt backlog tasksin Jira
How it felt
I made a solid dent in our backlogs (ESD, GitHub, Jira, Docs PRs) and was able to get a complete picture of our support surface. I learned a lot and it felt really good to serve the team this way. Even if the final form of the goalie is something totally different from what I envisioned, this time felt successful.
That said, the last month has also been very difficult. It was only while writing this post that I realized I logged almost 50 hours during the first full-time week of this rotation. That overage was, for the most part, attempting to stay on top of regular SDK engineer work. It didn’t feel like that could realistically be paused so I just absorbed the overage.
It was also very tough to universally triage GitHub Issues and PRs across our huge surface area. I tried to prioritize team PRs and get those out the door but the amount of time spend reviewing code across was exhausting. It felt like I was barely keeping up and, judging by the feedback, it showed.
Overall, I think a significant part of the negative effects I was feeling was (1) burning out on this role from planning/doing it for a month and (2) trying to do too much at once when I took it on 100%.
✅ What worked
There were a number of things that seemed to have a solid positive impact on the team. I would consider these votes for having a some kind of goalie.
ESD (internal suport ticket) triaging
ESD is not as scary as I thought. We do not get a lot of issues here and internal teams benefit greatly from a quick response from us. There were only 2 tickets out of around 20 that I triaged that I was not able to answer. I think it makes sense to always have an “owner” here.
Goalie backlog
Having a place to collect medium- to low-priority tasks that do not require a platform maintainer was a big improvement. This depends, of course, on the goalie having/making time to actually work through the issues (I did).
Default meeting facilitator
Having a default person to take down action items and decisions from our planning meeting, a default show and tell facilitator, and a retro task collector was beneficial. These things are notorious for slipping through the cracks.
Internal Slack channel triaging
Similar to ESD, I think having someone in here and watching the incoming requests is a great thing for internal teams and the company as a whole. I felt slightly less capable here than ESD but also knew I could reach out for help.
❌ What sucked
There were also a number of things that were not fun to take care of and did not seem to help the team all that much. My recommendation is to drop or overhaul everything here.
Lone PR reviewer
Being the only person reviewing all PRs and initial feedback from the team sounds like this part was not all that beneficial. Problems included:
- Being a bottleneck for team members
- Setting incorrect expectations with external submitters
- Review burn-out leading to poor focus and sub-par reviews
- Unclear process for transitions between engineers
GitHub issues to Slack automated feeds
GitHub issues are rarely urgent so an immediate ping is not necessary. It’s also a terrible way to keep track of what’s been handled and what is outstanding.
Quickstart feedback in general
Quickstart feedback in Slack makes even less sense than GitHub incoming. There were very few posts here that I could act on with a PR, the rest were just collected into Jira issues for the specific platforms. Nothing here is urgent and, in fact, these aren’t much different from quickstart labelled issues/PRs in the Docs repo.
🛠 What needs work
This section outlines where I think the best learning came from during this rotation. A huge problem with both of these is overall visibility and priority when compared to product work.
Handling new external GitHub Issues and PRs
After tinkering with the process and my approach and putting a lot of thought into it, there was just no way to treat the whole of our incoming GitHub work as a single feed for a single person. In one case, it took close to 3 hours to reproduce an issue that it would take a maintainer with an existing app ~15 minutes. I got through it and had fun doing it but, by the end, it did not feel like a good use of time.
The problem is that the issues and PRs just keep coming.
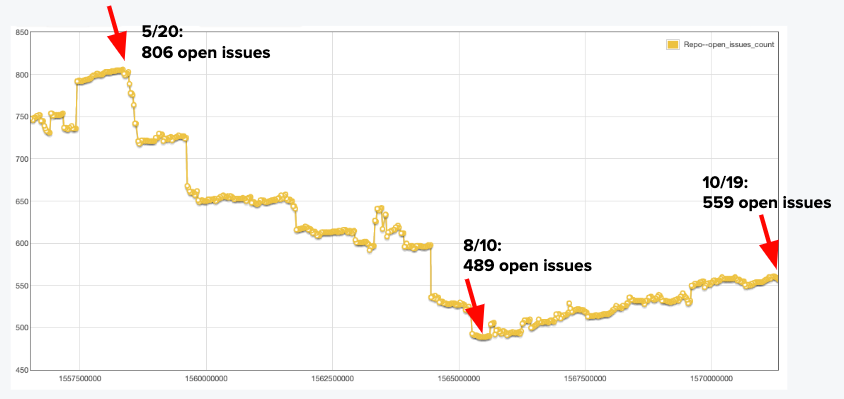
Recommended:
If we can agree that a platform maintainer is typically the most efficient and effective person to handle an issue or PR and that an initial triage is low value, then it’s a matter of figuring out what the general priority is for handling new issues in GitHub.
Platform maintainers should adjust their Watched repos to cover technologies they feel comfortable working in and use that along with the Review Requested page to surface new requests. Goal is no net growth of issues and engineers are responsible for raising a flag if they can’t keep up on their own.
To account for the time that this takes, we could consider the following:
- An max allotment of time, like 4 hours per week per engineer for GitHub issue burn down.
- A threshold of total issues which, when reached, triggers a burn down sprint.
- Basic monitoring and response when off rotation and focused burn down when on rotation.
Quickstart feedback and samples
Quickstarts are a large source of incoming work, including:
- Feedback comments from on-page widget
- Issues and PRs in the Docs repo labeled quickstart
- Samples issues, PRs, and Snyk dependency reports
- Regular CI breakage on PRs fixing the above
I would like to think that we are on our way to rethinking quickstarts/samples at large but, in the meantime, potential and existing customers are reporting problems.
This combined channel of issues is different from SDK issues are different for a few reasons:
- They are not urgent in the sense that they do not represent potentially broken production software
- They are often “drive-by” issues that are unlikely to be chased by the submitter
- Changes are complete once merged so overall handling time is typically lower
Right now, these are treated the same way and with the same priority as everything else. We don’t differentiate between quickstarts based on popularity, nor do we look for poor performers in our Tableau data.
Recommended:
We can generate reports that show all feedback for a specific application type or the specific quickstart itself. We should not be triaging feedback, sample, and Docs issues the moment they come in, but rather at regular intervals and combined for each quickstart.
We can calculate which quickstarts need the most attention based on amount of feedback and overall sentiment. Each engineer could have a list of prioritized quickstarts they are responsible for and tackle one per month (or more often if their GitHub workload is lighter). They would:
- Triage the feedback comments (via the report) looking for potential fixes
- Address all of the Docs Issues and PRs for that quickstart
- Address all PRs, Issues, dependencies, and CI problems for the related sample
🙌 Suggested Goalie shape
The shape I recommend this taking going forward:
- 50% time expectation
- Monitor and handle or respond and assign ESD tickets
- Monitor and handle or respond and assign
#dx-sdksposts - Work through GitHub Issues and PRs for watched repos only
- Work through Goalie backlog as time allotment allows
- Default meeting facilitator recorder
- PR reviews return to original process (everyone watch the queue)
- Ignore GitHub and QS feeds in Slack
< Take Action >
Comment via:
Subscribe via:
< Read More >
Tags
Newer
Jan 15, 2020
Notes from Rock Your Code Reviews with Dr. Michaela Greiler
I attended a great webinar led by Dr. Michaela Greiler on code reviews. I had my own opinions going in, of course, but I learned a lot and had a number of questions that I had (and didn't know I had) answered.
Older

Sep 08, 2019
Keys to Good Technical Documentation
Summary of the best comments in a Hacker News thread about technical docs.